《Reinforcement Learning : An Introduction》 Part I Tabular Solution Methods
这本书讲的很好,比较系统,适合自学,这里只是我摘录的一些笔记,供自己翻看,内容组织很乱,这本书网上有一些按章节总结的很具体的文章如需要可以搜索,有时间的话建议读原作:)
行为的奖励汇报增量计算:
\[ Q_{n+1} = \frac{1}{n}\sum_{i=1}^{i=n}R_i \\ \\ = \frac{1}{n}(R_n + \sum_{i=1}^{i=n-1}R_i)\\ \\ = \frac{1}{n}[R_n + (n-1)\frac{1}{n-1}\sum_{i=1}^{i=n-1}R_i]\\ \\ = \frac{1}{n}[R_n + (n-1)Q_n]\\ \\ = \frac{1}{n}[R_n + nQ_n - Q_n]\\ \\ = Q_n + \frac{1}{n}(R_n - Q_n)\\ \]
应对nonstationary环境
假设环境在发生变换,那么就不应该像上述描述的公式,给予每个reward相等的权重,而是给最新的reward较大的权重,
\[ Q_{n+1} = Q_n + \alpha(R_n - Q_n)\\ \\ = \alpha R_n + (1 - \alpha)Q_n\\ \\ = \alpha R_n + (1 - \alpha)[\alpha R_{n-1} + (1-\alpha)Q_{n-1}]\\ \\ = \alpha R_n + (1 - \alpha)\alpha R_{n-1} + (1 - \alpha)^2Q_{n-1}\\ \\ = ......\\ \\ = (1 - \alpha)^nQ_1 + \sum_{i=1}^n\alpha(1 - \alpha)^{n-i}R_i \]
这种增量计算的方式在这本书里被广泛使用,可以总结为以下的范式:
\[ NewEstimate = OldEstimate + StepSize*[Target - OldEstimate] \]
A Simple Bandit Algorithm

马尔可夫决策过程MDP
MDP和bandit不同在于,bandit仅需要评价动作,因为状态是不变的,而在马尔可夫决策过程中环境和过程是需要一同来看的
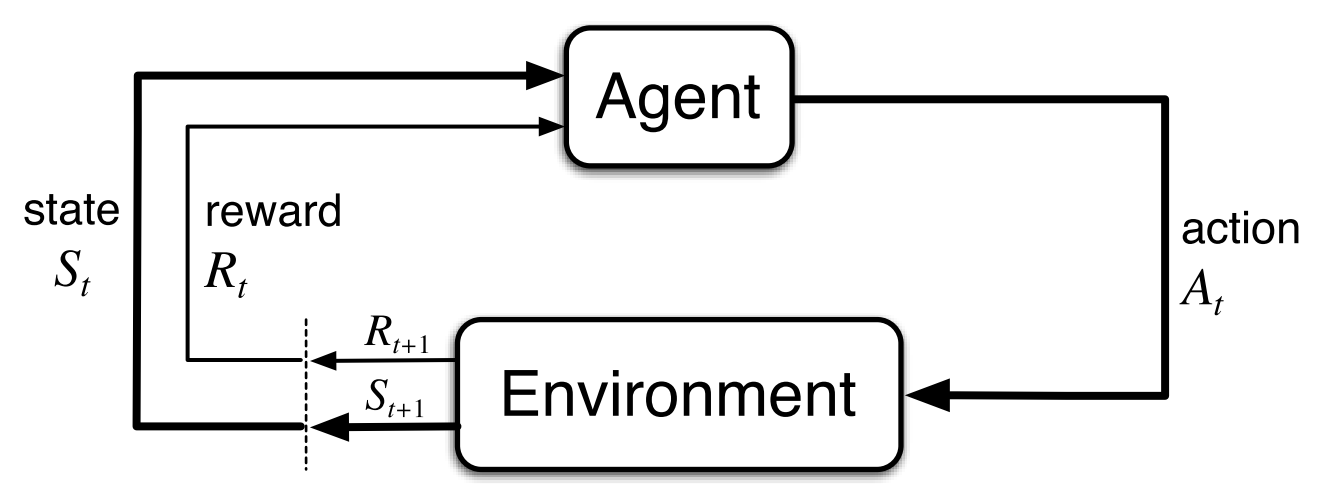
系统奖励设计小tip
系统的奖励设置不是存储我们希望agent如何达成目标的先验知识的好地方,比如下棋的游戏,如果我们对吃对方的子,控制棋盘中部地区等子目标设置奖励,那么agent很可能在下棋的过程中去追求达成子目标,即使可能冒着最终失去比赛的风险,奖励设置应该只表明想要达到的最终结果,而不表明如何达到最终结果,比如下棋中间状态奖励全部设为0,只有最终胜利状态是1,最终失败状态是-1
策略、价值、最优策略、最优价值方程
\[ v_\pi(s) = E_\pi [G_t | S_t = s] = E_\pi [\sum_{k=0}^{\infty}\gamma^kR_{t+k+1} | S_t = s]\\ \\ q_\pi(s,a) = E_\pi [G_t | S_t = s, A_t = a] \\ = E_\pi [\sum_{k=0}^{\infty}\gamma^kR_{t+k+1} | S_t = s, A_t = a]\\ \\ v_\star(s) = \max_\pi v_\pi(s)\\ \\ q_\star(s,a) = \max_\pi q_\pi(s,a)\\ \\ v_\star(s) = \max_{a \in A(s)} q_{\pi\star}(s, a)\\ \\ = \max_a E_{\pi\star} [G_t | S_t = s, A_t = a] \\ \\ = E_{\pi\star} [R_{t+1} + \gamma v_{\star}(S_{t+1})| S_t = s, A_t = a]\\ \\ = \max_a \sum_{s', r}p(s',r|s,a)[r + \gamma v_\star(s')]\\ \\ q_\star(s,a) = E[R_{t+1} + \gamma \max_{a'}q(s',a') | S_t = s, A_t = a] \\ \\ = \sum_{s', r}p(s',r|s,a)[r + \gamma \max_{a'}q_\star(s',a')]\\ \]
动态规划
策略评估
价值函数的计算可以通过递推公式进行一轮一轮的迭代更新直至收敛,需要提的一点是“in-place”计算,按照递推公式应该保留两个数组,一个数据存着当前轮的价值函数值,另一个数组存着基于上一轮价值函数计算下一轮得到新的值,依次交替计算,但实际使用中,用“in-place”的计算方式,即不额外存一个数组,直接把新的值复写老的值,这样除了更省内存之外,还会收敛的更快:

策略迭代
假设当前有一个策略\(\pi\)和价值方程\(v_\pi\),可以产生一个新的策略\(\pi'\),只要这个新策略基价值方程每一步都取贪心的结果,那么新策略一定是好于或等于原策略的,同时由于策略发生了变化,那么价值方程也一定发生了变化(见上述策略评估算法),会产生一个新的价值方程,然后又可以继续改进策略,依次改进直到收敛
\[ \pi_0 \overset{E}{\rightarrow} v_{\pi_0} \overset{I}{\rightarrow} \pi_1 \overset{E}{\rightarrow} v_{\pi_1} ...... \overset{I}{\rightarrow} \pi_\star \overset{E}{\rightarrow} v_{\pi_\star} \]

实践中,策略迭代往往可以在比较少的轮数就拿到最优解
价值迭代
策略迭代被诟病的点就是策略评估需要一些耗时,实际上这个策略评估的过程可以被截断(early-stop)并不影响收敛性,一种极端的方式是只计算一轮,这种方式就是价值迭代。
价值迭代是策略迭代的一种蜕化形式

异步计算tips
上述价值迭代和策略迭代都是对所有状态的顺序扫描,异步更新的意义在于可以以任意顺序更新state的价值函数,也就是说有些state可能计算了很多遍了,另一些state可能才计算一遍,但是为了收敛性,所有的计算也都是要计算到的,异步计算的好处在于迭代初期就可以更快体现效果
蒙特卡洛方法
蒙特卡洛方法不知道环境信息(对比动态规划方法),只依赖和环境交互的返回数据进行估算,比如不知道全局一共有多少个state,那么之前的迭代优化方法就不能工作了
蒙特卡洛方法不在step-by-step的进行更新,而是当整个episode完成之后才进行更新,更新策略是对episode产生的状态的所有reward进行平均
对比动态规划与蒙特卡洛方法
| 对比项 | 动态规划 | 蒙特卡洛方法 |
|---|---|---|
| 环境感知 | 已知所有的状态转移 | 仅仅感知在episode中出现过状态转移 |
| 状态转移计算 | 仅仅涉及到一步转移 | 当前状态一直到episode结束的所有转移 |
| 状态依赖 | 计算当前状态价值函数依赖其他状态价值函数(bootstrap) | 计算当前状态价值函数不依赖其他状态价值函数 |
蒙特卡洛方法的好处: + 可以从与环境交互(真实、模拟)的数据学习 + 状态价值的计算不依赖其他状态的价值,状态的价值计算彼此是独立的
策略评估
对于蒙特卡洛方法来说,因为没有环境模型,所以仅仅计算状态的价值函数是不足够的,必须要把动作结合进来一起考虑
系统没有模型信息,需要有一定能力explore各种不同状态,才能进行模型评估,这里假设每次模型评估开始都能选取一个随机状态(因为没有环境信息,所以很难,所以后面会有不做这个依赖的算法),策略评估如下:

注意之前提到的策略提升相关算法在选择新策略的时候都是贪婪策略,事实上策略提升框架本身并没有严格要求新策略一定是贪婪的,其实$\epsilon-greedy$也是可以作为新策略的方案的(书中给出了相关证明),这样就可以让蒙特卡洛方法拥有explore的能力,不必依赖于上面的exploring starts

on-policy和off-policy的区别
off-policy有两种策略,behavior policy和target policy,想要计算的是target policy而和环境交互的是on-policy,理论上on-policy是off-policy的一种特殊情况,即behavior policy和target policy是同一个。off-policy通常会收敛的慢一些,而且方差会比较大。
从上面的描述可以看出off-policy主要的需求点是从一个分布(behavior policy)中学习另一个分布(target policy),有一些常用的方法就是用来解决这个问题的,比如重要性采样(importance sampling),以下为与环境交互的一个序列的重要性采样公式: \[ \rho _{t:T-1} = \frac{\Pi_{k=t}^{T-1} \pi(A_k|S_k)p(S_{k+1}|S_k, A_k) }{\Pi_{k=t}^{T-1} b(A_k|S_k)p(S_{k+1}|S_k, A_k) } \] 这样最终计算价值函数的公式为: \[ v_\pi(s) = E[\rho _{t:T-1}G_t |S_t=s ] \] 这个式子里期望的计算方式可以用ordinary importance sampling的方式: \[ v_\pi(s) = \frac{\sum_{t\in\tau (s)}\rho _{t:T-1}G_t }{|\tau (s)|} \]
也可以用weigted importance sampling的方式: \[ v_\pi(s) = \frac{\sum_{t\in\tau (s)}\rho _{t:T-1}G_t }{\sum_{t\in\tau (s)}\rho _{t:T-1}} \]
对比ordinary importance sampling和weigted importance sampling
用ordinary importance sampling做估计通常收敛无偏估计,但是方差比较大,而weighted importance sampling则相反,通常实际使用中喜欢方差小的算法,但ordinary importance sampling还有一个优势是比较容易融合到函数近似的算法中去
增量更新
ordinary importance sampling的增量更新很容易,这里写一下weighted importance sampling的增量更新方式: \[ V_{n+1} = \frac{\sum_{k=1}^nW_kG_k}{\sum_{k=1}^nW_k} \\ \\ = V_n + \frac{W_n}{C_n} (G_n - V_n)\\ \] 其中 \[ C_{n+1} = C_n + W_{n+1} \]

关于蒙特卡洛方法支持explore的方式小结:
- 最前面提出了用随机起点的方式(Expoloring Start),但是这种方式要求系统对环境模型有认识,而蒙特卡洛方法是没有这个属性或者要求的
- 用\(\epsilon-greedy\)的policy去做on-policy算法,因为引入了\(\epsilon-greedy\)所以增加了explore的可能性,不在需要第一条的假设
- 用off-policy的方法也可以去掉第一条的假设,因为off-policy区分target policy和behavior policy,而behavior policy可以引入随机性进行探索
策略优化
下面算法注意on-policy是off-policy的一种特殊情况

总结蒙特卡洛方法对比动态规划方法
- 蒙特卡洛方法不要求有环境模型,动态规划必须要有
- 蒙特卡洛方法可以利用agent和环境交互产生的数据集,这些数据集的获取通常是很便宜的
- 蒙特卡洛方法会把主要的计算量放在重点的状态上,而不是像动态规划方法那样每轮迭代都要过一遍所有状态
- 蒙特卡洛计算一个状态的价值时候,不依赖于其他状态,这样就不会引入其他状态估计不准确带来的偏差,也即蒙特卡洛方法不做bootstrap
时序差分方法(Temporal-Difference Learning)
时序差分方法是一种综合蒙特卡洛方法和动态规划方法的一种方法,它像蒙特卡洛方法那样不需要环境模型,使用和环境的交互数据进行评估,同时它又像动态规划方法一样可以尽快更新参数模型,而不需要像蒙特卡洛方法那样等到最终的结果才进行估计
时序差分方法不需要像蒙特卡洛方法一样等到最终结果才能更新价值函数,这里对比一下两种方法的更新公式,蒙特卡洛必须要等到最后是因为只有到最后\(G_t\)才能确定,而时序差分选择用\(R_{t+1} + \gamma V(s+1)\)来替代这个值
\[ V(s) = V(s) + \alpha[G_t - V(s)]\\ \\ V(s) = V(s) + \alpha[R_{t+1} + \gamma V(s+1) - V(s)] \]
来自知乎的评价MC和TD https://www.zhihu.com/question/62388365 认为MC更适合学习很长期的任务如围棋,TD更适合短期的如维持倒立摆的平稳。
一个例子对比TD和MC,给定如下几个序列,每个序列以
这个例子中对状态A的价值评估,两种算法不同:
MC:从A出发所有的最终奖励都是0,所以A状态的价值就是0
TD:从A出发是100%到达B的,B的价值是0.75,所以A的价值也是0.75
这样看,MC的目标是最小化训练数据误差,而TD看重的是马尔可夫过程的最大似然
策略评估
TD(0)

TD(n)

策略优化
Sarsa(State–action–reward–state–action)

Q-learning(off-policy)

一个例子对比Sarsa和Q-learning:
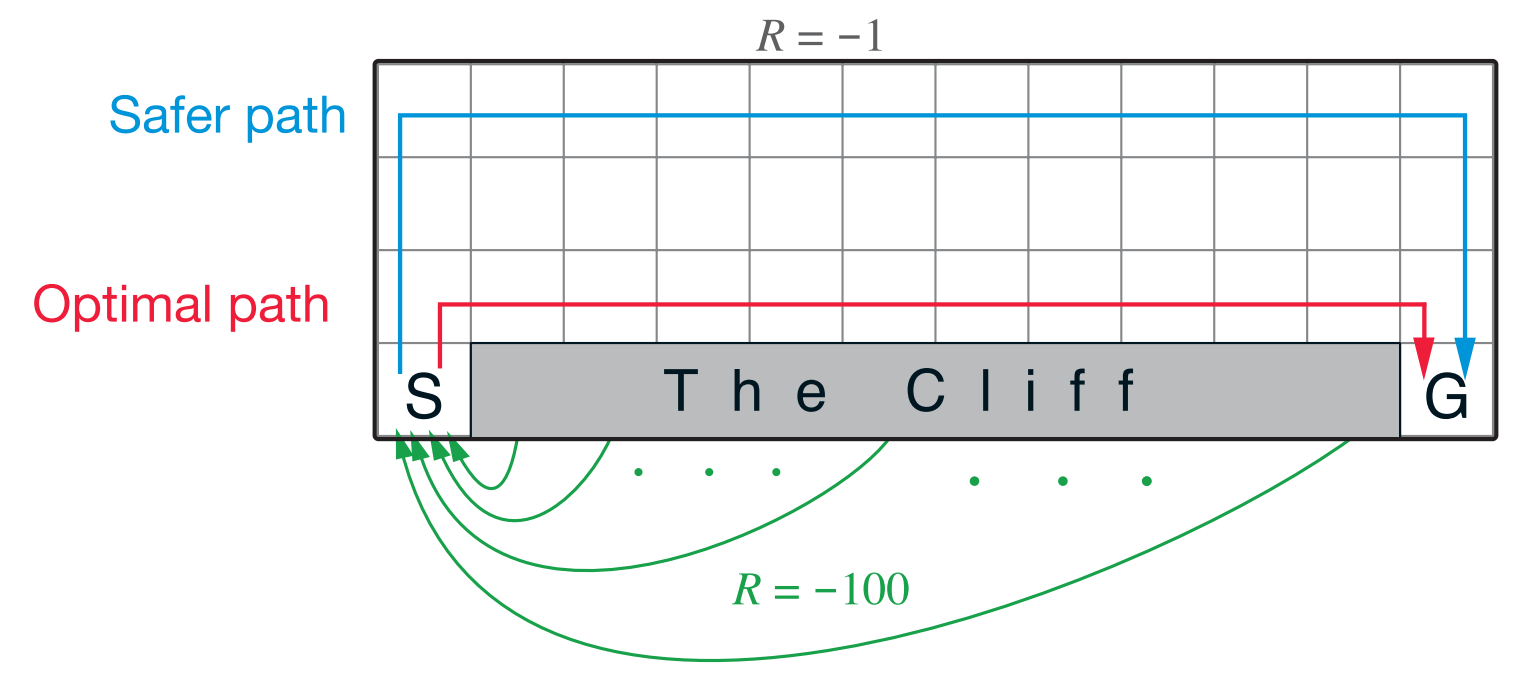
在这个经过悬崖的路径规划过程中,Sarsa会选择最安全的路线(因为它是期望的方式计算价值),而Q-learning会选择最短的路线规划(因为它的策略是选max的)
Expected Sarsa:
对Sarsa更新时候做一个小变化取期望而不是sampling,注意这时expected需要另一个behavior policy所以实际上expected sarsa属于q-learning
\[ Q(S, A) = Q(S, A) + \alpha[R + \gamma E[Q(S',A') |S'] - Q(S,A)]\\ \\ = Q(S, A) + \alpha[R + \gamma \sum_a \pi(a|S') Q(S',A') - Q(S,A)] \]
如此修改带来的好处是: + Expected Sarsa的步长即使设置为1,也是可以保证收敛的,而不像Sarsa要求步长设置的很小 + Expected Sarsa需要的数据集的量比Sarsa也要小,因为Sarsa是依靠一定的随机性,而Expected Sarsa是靠期望,因此Expected Sarsa收敛的也更快
n-step Sarsa:
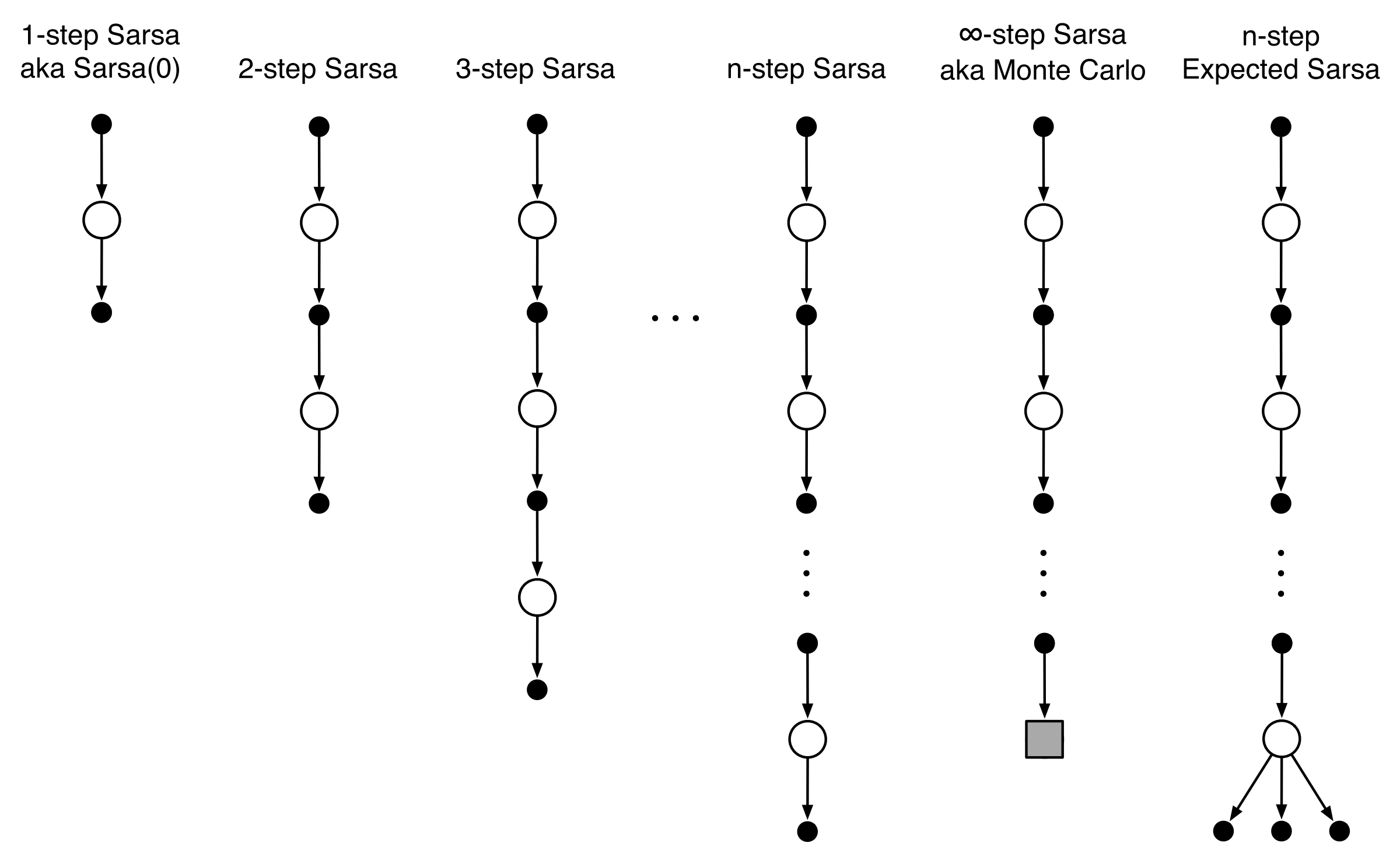

n-steps Q-learning(off-policy)

n-steps Q-learning without importance sampling
使用importance sampling的原因和蒙特卡洛方法一样,都是没有穷尽在每个状态下的所有可能,在时序差分里可以通过对未探索的状态使用估计值来替代:

Dyna-Q 统一model-learning和model-free的方法
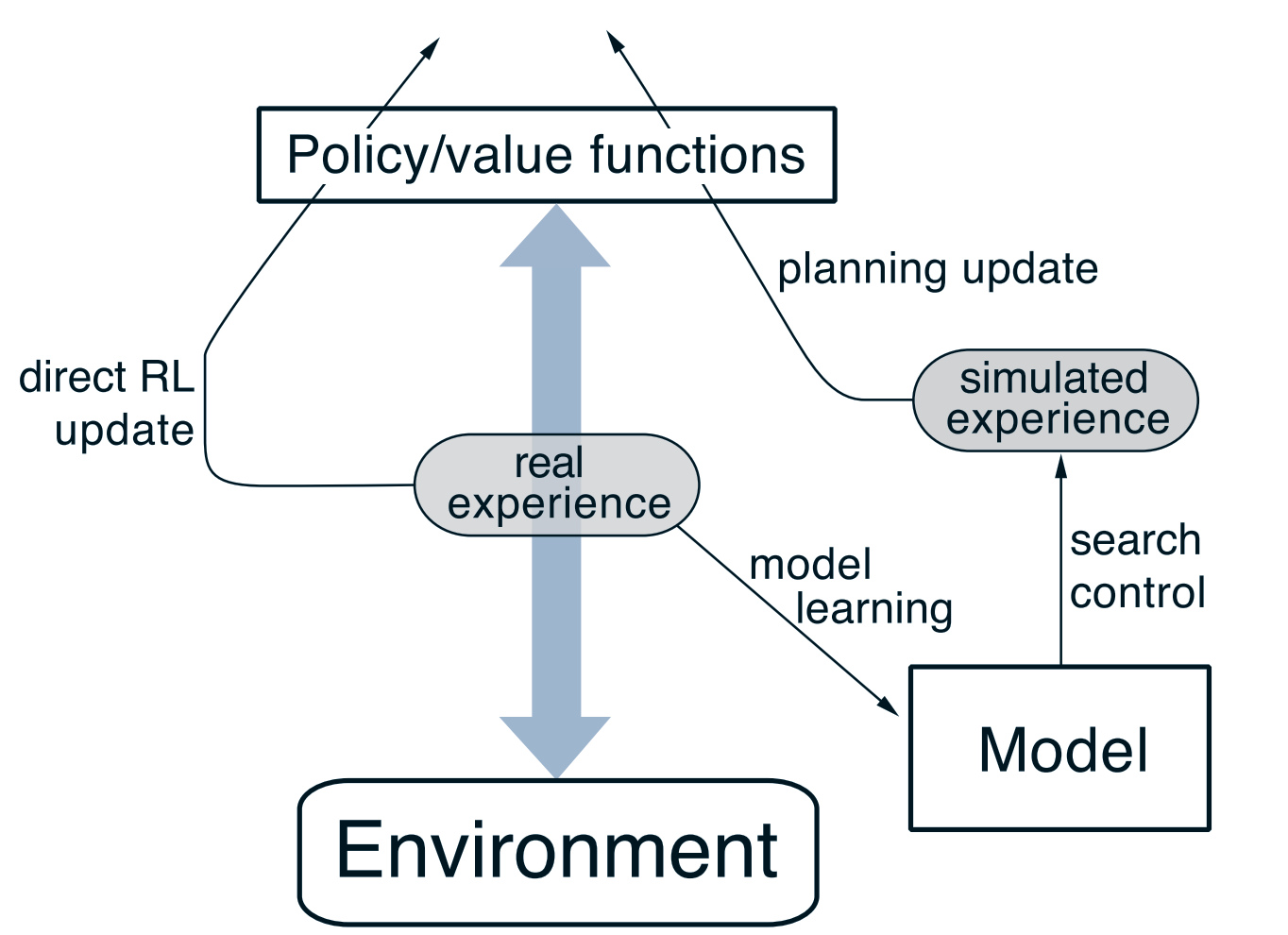

启发式搜索
系统建立的价值函数v或者状态-动作函数q都是一种估计,不能保证是完美的估计,如果这两个函数是完美的,那么agent在应用时只需要看一下当前步骤的最优选择即可,但因为是不完美的,所以agent进行更深更广的探索后选出的行为通常会更好。
rollout policy
在决策阶段rollout policy采取类似蒙特卡洛的方法对每个状态的结果求平均,认为是这个状态的最终值
MCTS
蒙特卡洛树搜索是一种rollout policy的特殊形式,它强调在高价值的路径上多进行一些尝试(因为决策时间有限,希望把时间放在有价值的搜索区域)
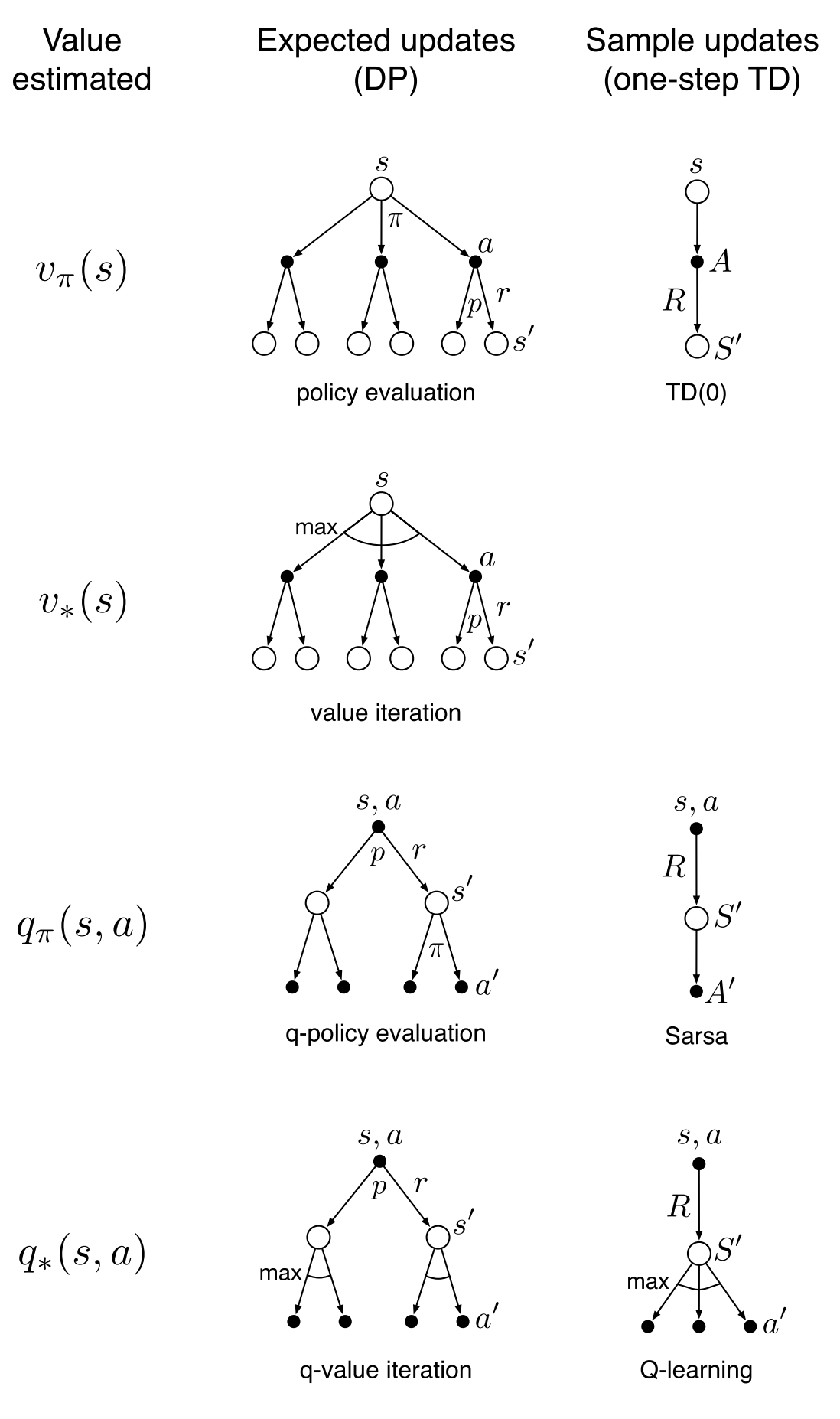
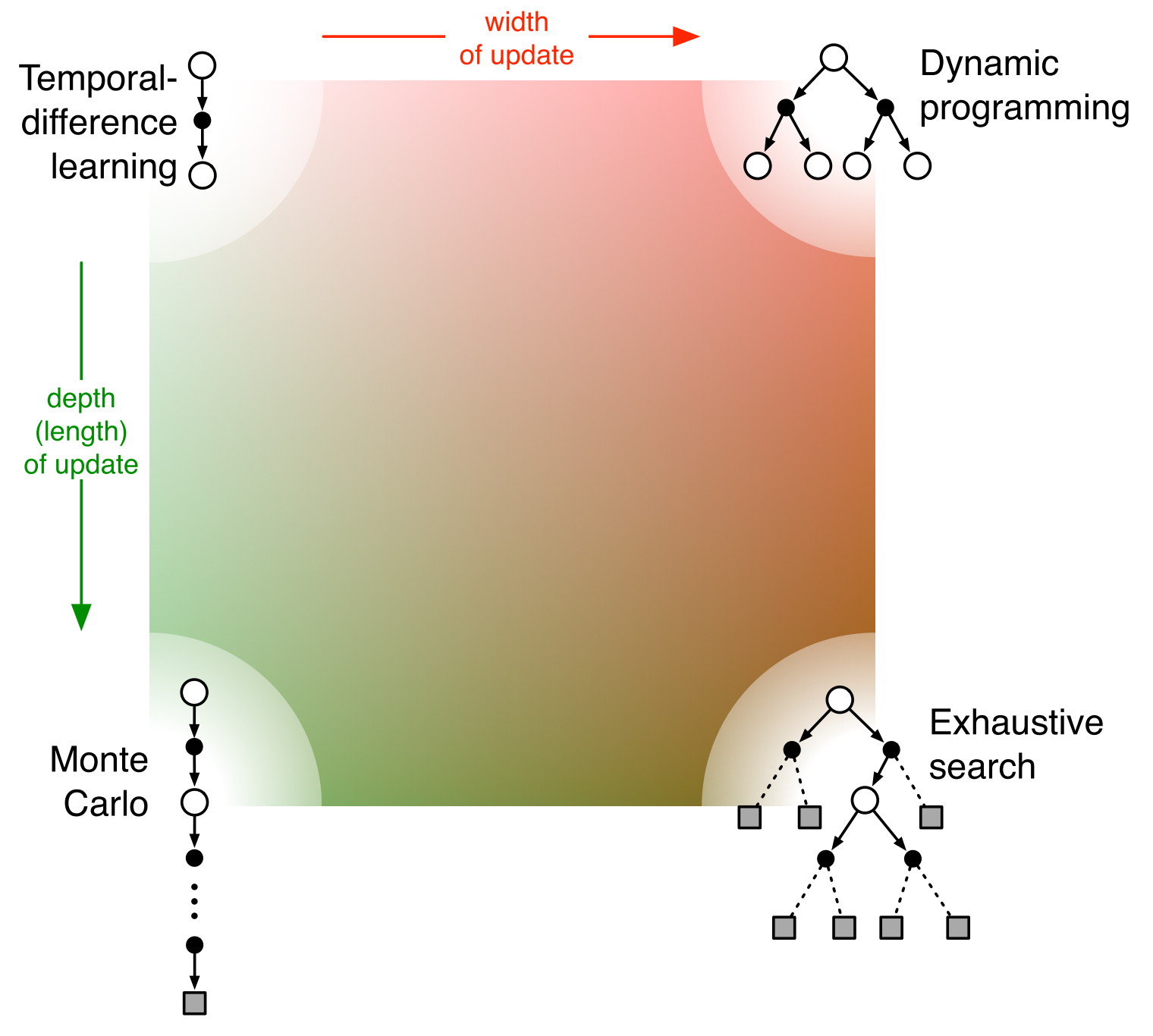
上述集中算法对比图
联系我: