GTC-China-2018总结
今年是头一次参加GTC,感觉非常有收获,2019来之前补上笔记吧。
一些名词说明
cudnn
- 实现了一些神经网络的层,速度要求至少要跟最快的blas库差不多,内存要显著使用的少
- 用于training阶段的优化提速
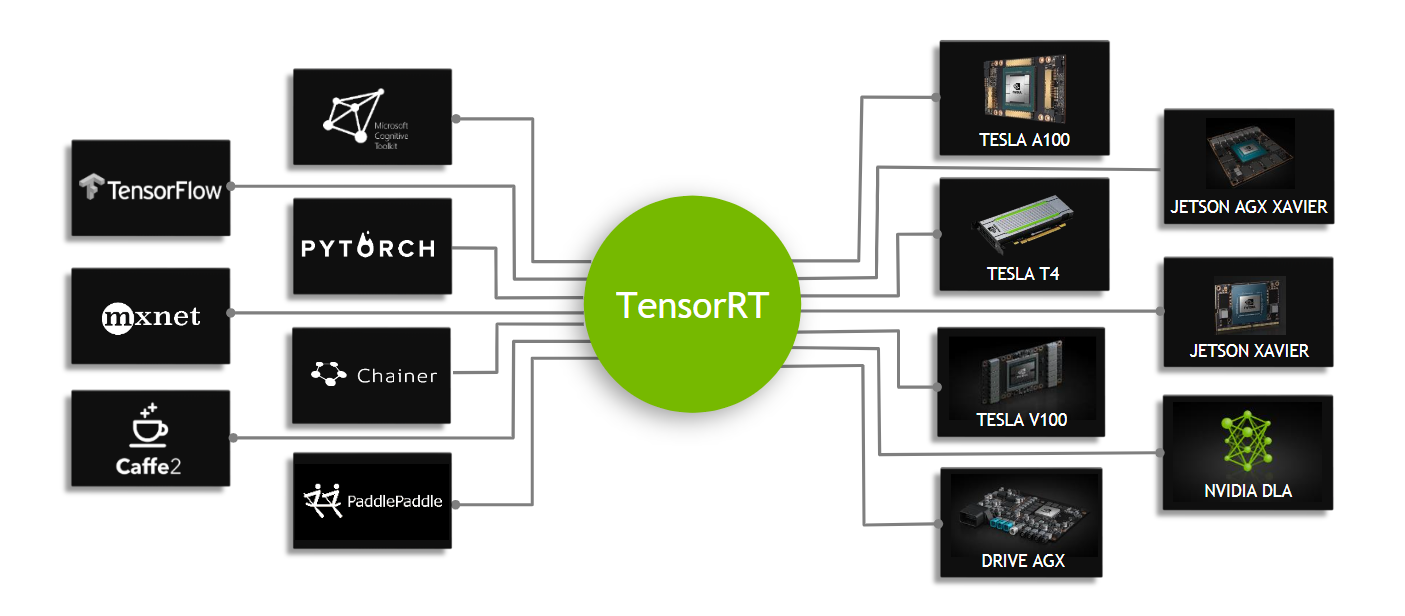
tensorRT
- 对比cuDNN,tensorRT追求Inference的速度
- TensorRT is a high performance neural network inference optimizer and runtime engine for production deployment
- tensorRT会主动去合并一些layer并且会根据layer去选择最佳的底层模式去运行,提高吞吐、减小延迟、降低功耗,降低内存使用,如果允许配置允许还会用低精度运行。
- tensorRT有build的阶段和inference阶段,build阶段可以生成plan file在后续阶段使用,不同硬件平台plan file不能公用
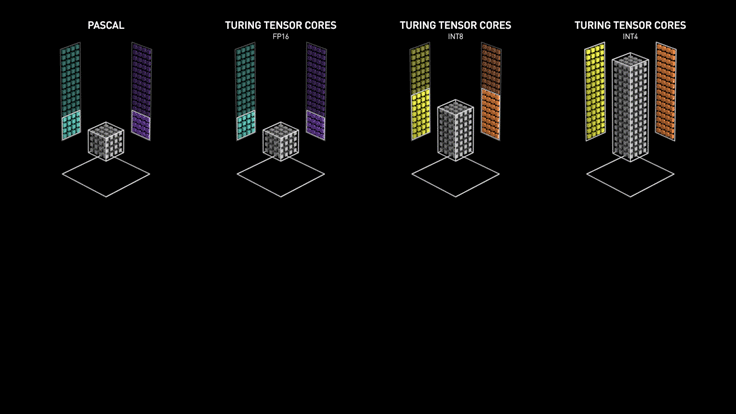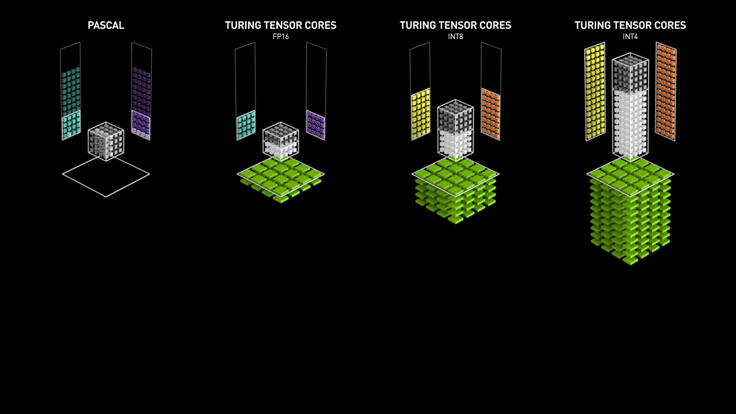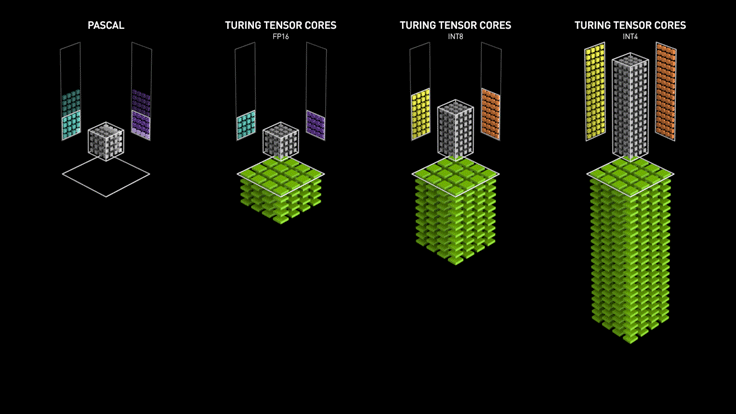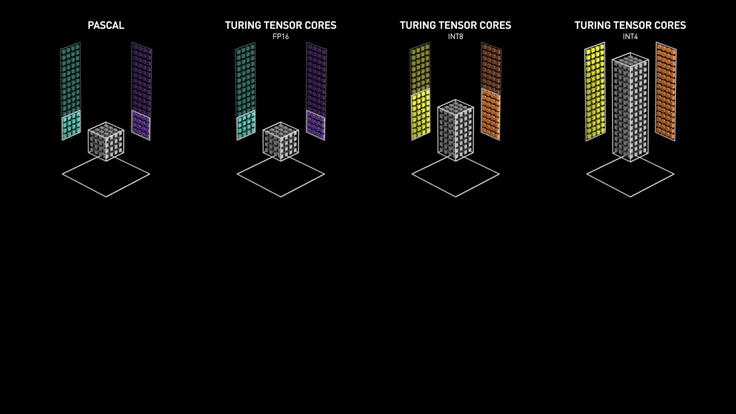
tensorCore
- Tensor Cores can accelerate large matrix operations, which are at the heart of AI, and perform mixed-precision matrix multiply and accumulate calculations in a single operation. With hundreds of Tensor Cores operating in parallel in one NVIDIA GPU, this enables massive increases in throughput and efficiency
- 专门优化GEMM的硬件,一个clock可以完成比以前更多的操作
- Tensor Core执行融合乘法加法,其中两个44 FP16矩阵相乘,然后将结果添加到44 FP16或FP32矩阵中,最终输出新的4*4 FP16或FP32矩阵,被称为混合精度
- 这个gif图比较形象:
deepstream
- DeepStream SDK on Jetson uses Jetpack, which includes L4T, Multimedia APIs, CUDA, and TensorRT. The SDK offers a rich collection of plug-ins and libraries, built using the Gstreamer framework to enable developers to build flexible applications for transforming video into valuable insights. DeepStream also comes with sample applications including source code and an application adaptation guide to help developers jumpstart their builds.
- Developing IVA applications for complete scene understanding entails creating multimedia processing graphs and orchestrating the dataflow of multiple DNNs working in sync. This can be a complex and time consuming process. This SDK is designed to remove the complexity, so you can focus on application development. By leveraging the Gstreamer plug-in architecture, DeepStream makes it easier than ever to combine image capture, encoding, decoding, scaling, and inference using TensorRT. The architecture lets you utilize all of Jetson’s hardware capabilities to maximize throughput and performance. By leveraging Jetson’s unified memory architecture, DeepStream SDK enables you to reduce memory management overhead and deliver low latency solutions
Isaac
- 我最感兴趣的是Isaac Sim,一个仿真器,仿真是技术落地的圣杯级产品,要重点研究下这个Isaac Sim
- 官宣:Isaac Sim 可使开发人员在极为逼真的虚拟环境中训练和测试他们的机器人软件。
dlss
- 英伟达提供的上采样的技术,你只需开发2k画质的游戏,利用英伟达的技术可以上采样到4k画质,这样可以利用更少的计算资源达到更好的体验
rapids
- 数据挖掘库,像python一样数据挖掘
- pandas-like api
- sklearn-like api
xavier的七种处理器
- ISP(图像传感器处理单元)
- PVA(可编程立体视觉加速器)
- VPU(视频处理器)
- OFE(光流引擎)
- tensorCore(可编程张量处理器)
- CUDA(并行加速器)
- DLA(深度学习加速器)
- CPU
21日下午无人驾驶session
1、drive av:自动驾驶软件架构, nvidia
drivenet
obstacle track—openroad net
lane net + tracking + fusion
- 三个相机
- lane assignment(Object In Path Analysis)
localization
- camera/lidar + hd map
summary
- one architecture
- safety
- security
- real time (target:30帧,目前20)
- high accuracy
- customizable
QA
- xavier支持多传感器同步有统一授时
- 用hd map结合多feature进行绝对定位,防止误差累积
- tx2勉强支持,不够实时,xavier才可以支持,xavier会有低配版低成本,也可以支持
- 整个代码还在优化,19年会发布,目前也可以用,但还未到最满意状态
- 所有的代码会在开发套件中包含
2、the hardest problem in self driving 智加科技
- 做卡车,可以fix在高速公路上,L4
- 所有车代码相同,可能一起挂(2012年leap-second bug)
- 测试:需要大量测试、很难轻易去测试、新版本发布重测、仿真不足够说明问题
- 可靠性:sensor fail,software bug,design to fail safe
- 冗余和自动维护清洁
- sensor soft failure
- out of focus
- loss of one color
- delayed output
- 冗余
- 方法的冗余
- 视觉里程
- 惯性里程计
- 雷达里程计
- fault detection and isolation(fdi)
- 软件多版本冗余
- 波音forward recovery,高性能版本被约束在简单版的范围里
- 用watchdog和safe landing system来保证系统在安全状态下
- safe landing system有接管权限:立刻停止、靠边停止
- deep learning在新场景的泛化情况
- 不能光用benchmark,不停的刷新测试集
- coq system的kernel有3000行,逻辑验证和证明有10w行
- TLA+,被用在亚马逊检查系统bug
3、保护性自主驾驶研发进展, SF Motors
- 车辆数据收集及车载空中升级OTA
- 系统:
- 可靠设计
- 足够的冗余和失效保护
- 软硬件仿真
- 系统集成、测试、数据采集分析
- 硬件
- 多传感器融合
- 实时运算系统提供处理能力
- cpu、gpu、fpga、安全芯片
- 运算系统有冗余,双备份cpu、gpu、fpga
- cpu、gpu、fpga、安全芯片
- 软件
- 感知、摄像头、激光雷达、高清地图
- 地图规划,实时决策
- 运动控制
- 仿真
- 路测
- 模块化设计全栈式集成
- 传感器标定
- 数据同步采集
- 环境感知
- 传感器融合
- 地图及定位
- 路径规划及决策
- 车辆控制
- 打通完整链路、闭环仿真、封闭和开放测试
- 车道线检测:
- 有一些常用数据集、主流方法survey
- 用多种数据训练
- 先做语以分割(DL),再做车道线检测(cv)
- 网络叠加
- 测到检测只有一层,避免加大latency
- 路径规划
- 行车线生成
- 变道决策
- 基于采样的路径规划
- 控制
- 反馈
- 前馈
- 延时补偿
- 误差边界监管
- 控制结果
- 50公里以下,直行小于5cm,弯道12cm
4、autoX 自动驾驶在物流领域的应用,autoX
- 50公里以下,直行小于5cm,弯道12cm
- 40线激光雷达+6个摄像头
- 自己设计硬件同步系统nm级别
- 技术实力:连续行驶7个小时,一镜到底
-
观点:中国驾驶环境没比美国差;说自动驾驶达不到是自己技术不行:(
- 跑一遍就可以三维见图,有自己独特的优化定位系统
- 冗余定位:基于激光雷达+基于视觉定位
- 实时环境感知
- 快,神经网络分割15ms/帧,网络优化,tensorRT+cuDNN(不用tensorflow做inference)
- 融合高清地图和环境感知
- 识别临时指挥交通的指令
- 识别物体方向
- 远程监控与控制,4G网络传输4个高清摄像头50ms
- 自主研发高速线控系统
- 多传感器三维仿真
- 中国:美团、中通合作在园区进行低速配送(15km以下)(i7+gtx1070)
- 美国:物流:送包裹、送外卖、生鲜
22日selected talk
开发者应用:tensorRT部署快速应用 ,nvidia
- 单个clock完成4x4的fp16矩阵乘加gemm
- fp32跟tensor core没关系
- 主流DL框架对训练已经成为主流,但一般框架对推理未做深层次优化,用tensorRT来解决
- tensorRT高性能DNN推理软件库
- resnet50,v100tensorflow:305Images/Sec,latency:6.67,tensorRT:5700Images/Sec,latency:6.83ms,40xFaster,一般应用可以达到3~10倍
- tensorRT优化
- 支持fp16/int8,充分利用tensorCore
- 自动选取最优kernel,矩阵乘法卷积有多种cuda实现方式,根据数据大小和形状自动选取
- 计算图优化:kernel融合,减少拷贝等,如:
- 少调一些kernel,每一层可能很简单,合并之,减少调用kernel浪费和数据拷贝,数据无关图并发执行,计算会进行分析融合
- 通过mxnet或tensorflow集成tensorRT
- 易使用
- 不能达到最优效果,因为tensorRT不能支持某些层
- TRT兼容计算被打散,不支持TRT的层仍要用传统方法,数据重复拷贝
- 从现有框架导出模型,再导入TRT
- 适中,用于于外部框架
- 使用TRT C++ API自行构建
- 适应性最强,效率最高
- 难度最高
- 自定义网络层,以tensorRT plugin的形式,使用cuBLAS/cuDNN/NPP/Cuda C来实现
- 推荐使用fp16和int8
- QA:
- workspace的设置只能试,没有api告诉我们实际需要多少,可能后续会增加
- 虽然支持rnn,但变长支持的好像不是很好
- 大部分tensorRT里的层都是重写的,为了kernel融合,没用cuDNN,cuDNN达不到tensorRT的效率
- nvprof可以看tensorCore是否被使用
- tensorRT暂时不会开源,会逐渐披露细节和实现原理
软硬一体的apollo compute unit,baidu
- 功能:
- pilot
- valet parking
- self localization
- intelligent map
- ACU三种规格(功能逐渐加强,商业模式):
- basic
- advance
- professional
- ai algorithm + soc software + mcu software + 车规硬件
- 百度对行业认识和分层理解
- 算法工程师眼中,汽车工程师眼中,硬件工程师眼中
- 自动驾驶可行性
- 什么是冗余和安全
- 驾驶策略上偏保守,负责
- 硬件视角:
- camera
- ultrasonics
- radas
- hd map
- 内部各种校验,可降级
- hw->bsw->app->support
- classical autosar
- nv drive架构推荐
- 去ros化
腾讯强化学习研究最新进展:sim-to-real, 腾讯
- 分布式架构
- generation 1 : learner和actor分离
- generation 2 :
- 服务器闲时工作,actor随时创建和销毁
- sync-sgd:zeromq+naccl(nvidia)
- ???居然是同步的???
- 训练场
- 训练游戏ai
- 评测:Doom射击游戏
- combo-action
- reward shaping
- find new enemy
- pick up useful items
- make dispacement(exploration)
- lose health
- starcraftII
- TStarBot,techreport2018
- 强化学习胜率比较高,但一些规则bot更猛
- 机械臂
- 建立仿真器,满足物理属性
- hierachical reinforment learning
- sub goal;sub reward;divide and conque
- self-tought learning for Optical flow(DDFlow AAAI-2019)
边缘侧开源深度学习—DLA介绍 ,nvidia
- introduction
- Deep Learning Accelerator
- fix-function for deep learning inference
- 深度优化:image(cnn)
- 支持(不是深度优化):rnn(lstm)
- scalability
- 场景固定
- 硬件级别支持
- accuracy
- 硬件设计上保证fp16,int8也达到尽可能高的精度
- 实验结果低精度效果降低很少(googlenet、alexnet)
- flexibility
- 内部的optimizer完成:内部会做layer合并,各种优化保证效率,数据内存使用的高效
- efficiency
- data reusablity
- partial adder tree
- localize datapath
- sparsity
- HW/SW/System architecture
- HW
- 30cycles做完convolution
- large and hierachical buffering strategy
- SW
- System
- System=Compiler+Runtime+Hardware
- 全系统保证效率
- 后续会整合到tensorRT中
- 第二代DLA硬件架构开发中ing
- HW
- edge computing (nvidia full support : TensorRT)
- edge device:sensor->computing->act/react
- close to data/decision,high quanlity of action/reaction ~ nvdla build/compiler/parser/optimizer
- fixed scenario pre-defined ~ nvdla user-mode driver
- latency sensitive ~ nvdla kernel-mode driver
- cost sensitive(area/power) ~ nvdla hardware
- DLAOpen VP(virtual platform) and FPGA
- 可以去亚马逊FPGA平台去部署
nvidia drive works, nvidia
- accelerated low level 2d image processing capacities
- multi-camera color correction
- feature detect
- feature tracking(2d),…
- structure from motion
- video rectification
- stereo rectification and dispartiy est
- point cloud processing modules
- hw acceleration
- low level support to all driveworks software development
- recording and replay tools
- tool for processing map data
- mapStream & …
- xavier:
- dla, pva, isp, codec, gpu, multicore cpus
- dw framework
- 参考了ros的节点架构设计
- 三大模块:drive core,drive network,drive-calibration
- drive works 支持tx2,xavier
联系我: