这篇paper《The Case for Learned Index Structures》是google brain的一个工作,所以网络上流传的也比较广,这两天看了,是比较新颖的一个话题。如作者所说,目前的工作尚不能去取代传统的数据库索引方式,但是用机器学习的方法来建立索引确实给这个研究了几十年的经典问题指出了一个新的研究方向。
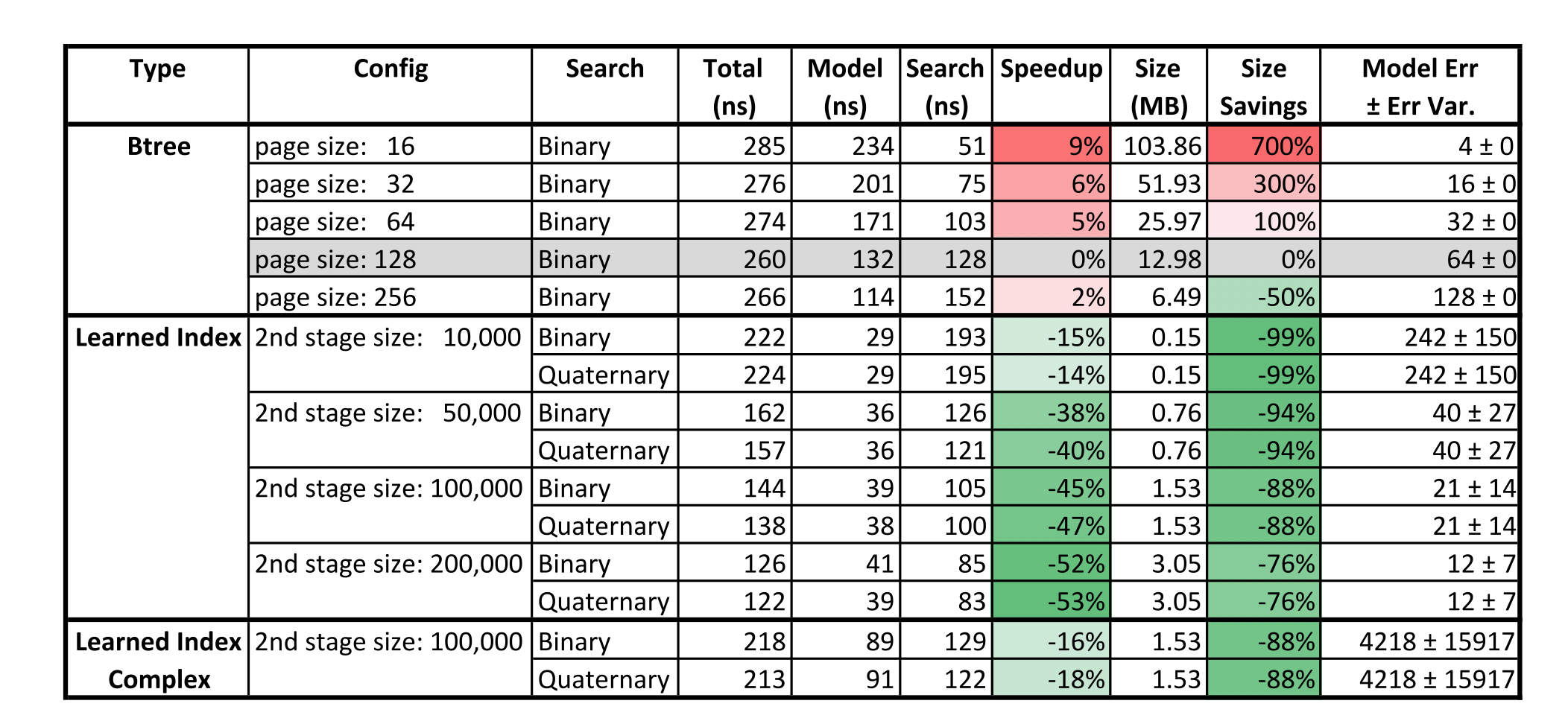
B-tree可以理解为一个机器学习概念中的“模型”,它的输入是索引的key,返回是索引key对应的数据存放位置。数据库使用B-tree作为索引时,为了减少索引数据量,不是针对每个key都进行了索引,而是把待索引的数据排好序,每n个key值取一个建立索引,这样既可以减少索引数据量,而且搜索索引时实际要找的值位置与搜到的结果之间不会偏离太远,这样B-tree模型与机器学习中的回归树模型看起来就很相似了,两者都是尽力拟合数据,但还是可能会有一定的误差范围,两者的类比如下图:
同时在大量的数据更新或插入后,B-tree需要进行re-balance操作也可以类比于机器学习模型的re-train概念。
传统的基于B-tree的索引建立方式,算法上考虑的是最差情况的效率可以保证O(logN),而忽略了实际数据的分布形式,举个极端的例子,需要建立索引的数据是连续的自然数,那么按照这个数据规律去搜索数据可以达到O(1)的效果,要好于O(logN)的效果。机器学习的方法在fit数据分布上相比于B-tree有独特的优势,从这个角度讲,机器学习方法是有建立更好的索引效率的理论可能性的。
此外,CPU的摩尔定律已经失效,而GPU的效率还在持续提升,机器学习方法的模型可以借助于GPU的强大计算能力和发展前景,进一步提升索引效率。
针对2亿条web-server日志建立索引,使用的模型是用tensorflow训练的呃有两层隐含层(每层32个节点)全联接的神经网络模型,激活函数使用ReLU,时间戳作为输入,实际数据位置作为输出。对比结果是B-tree数据查找需要300ns,而神经网络耗时8000ns。机器学习模型落败,分析原因如下:
上面的问题分析发现“最后一公里”问题是性能影响的瓶颈,上亿条的数据使用一个模型来fit会比较困难,所以提出使用一个层次化的专家模型来解决这个问题:
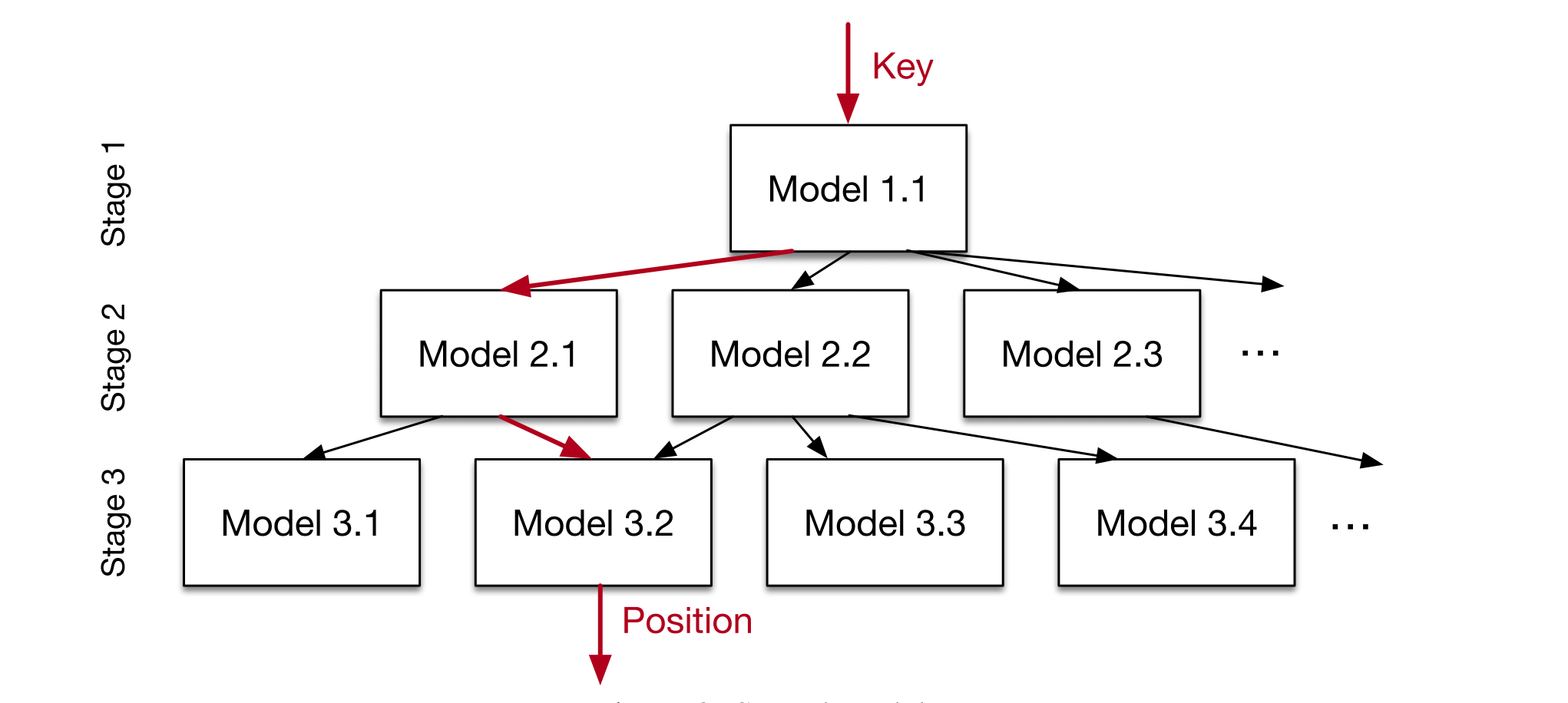
定义模型为\(f(x)\),\(x\)为索引值,\(y \in [0, N)\)表示数据位置,\(M_l\)表示stage \(l\)层的模型,\(f_l^{(k)}(x)\)表示stage \(l\)层的第k哥模型。
定义目标损失函数为:
\[ L_0 = \sum_{(x,y)} (f_0(x) - y )^2 \]
\[ L_l = \sum_{(x,y)}(f_l^{\lfloor M_l f_{l-1}(x)/N \rfloor}(x) - y)^2 \]
这个模型解决了单模型表达能力的限制问题,同时也像B-tree一样,具备了把数据分段的能力。
基于stage这种特性,可以设置混合模型来更好的对数据建模,第一层需要比较复杂的表达能力,更适合选择神经网络来建模,下面的层使用线性回归来避免过长的计算时间,为了彻底根治“最后一公里”的问题,如果最底层模型的误差的界比较大,就再用B-tree来控制误差范围,具体模型训练算法如下:

实验结果如下图: