纸上谈兵YARN、Spark、Storm、Flink
在之前搜狗工作写的程序百分之八十都是Map-Reduce程序,对当时的Hadoop 1.x框架还是很熟悉的,也一直在关注着大数据模型业界动态。近些年在快仓一直因为业务规模相对比较小,程序都是单机部署,对新的流行的大数据模型虽有耳闻,却一直没有进一步了解。这段日子在想智能化仓库的调度系统云端解决方案到底是什么样子的,之前写过一篇关于Mesos应用的思考,借这个机会也调研了几篇现在应用比较广的框架论文(YARN、Spark、Storm、Flink),参考论文见最后的Reference部分,并没有深入实践过,纸上谈兵容易忘记,记录下来。
为什么一定要云端发布呢?
本地发布也有很明显的优势:
- 影响范围非常容易控制
- 因为toB业务定制化纷繁复杂,独立部署多分支维护便利
- 网络环境可靠
- …
我理解云端的好处是:
- 发布方便
- 调试方便
- 服务器硬件资源共享
- 运维方便
- …
凡事都有利弊,云端是不是更好,以及什么样的云端架构更合适都需要更大的智慧,这不是这篇文章纠结的点
YARN
Hadoop 2.0之前的Hadoop平台是一个为Map-Reduce定制的计算平台,虽然取得了巨大的成功,但也遇到了不少问题,《Apache Hadoop YARN: Yet Another Resource Negotiator》这篇文章列举了“十宗罪”,2.0进化出了YARN平台,可以说是十分了不起的架构升级,最主要的工作如下:
Hadoop 1.x阶段备受争议的JobTracker设计被拆解为了独立的两块:Resource Manager和Application Manager。这个架构升级让YARN不仅仅是支撑Map-Reduce的运行平台,包括后面提到计算框架也都可以运行在YARN平台上。
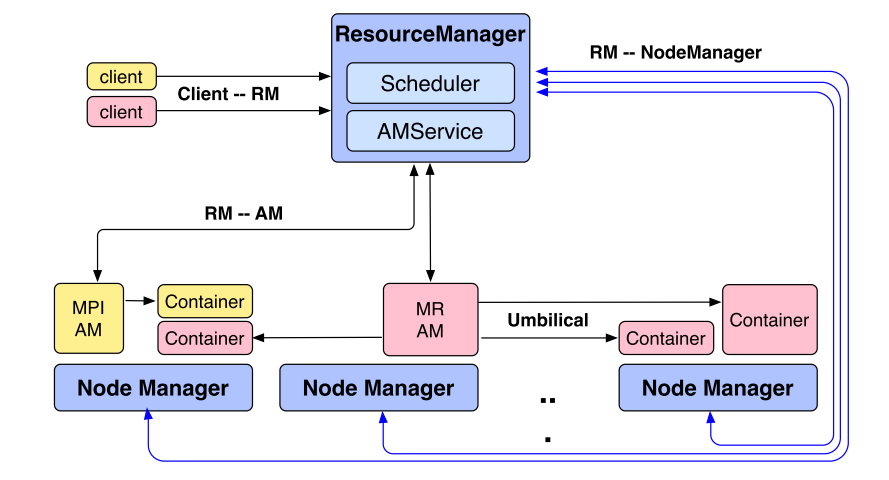
在新的YARN架构上,抽象出下面几个主要模块:
Resource Manager
Resource Manager会做:
- RM(Resource Manager)会从Node Manager上报的信息中统计出整个集群全局的资源信息
- 负责根据全局任务运行情况分配每台机器上运行多少个container,每个container包括一些cpu、内存资源
- RM对外提供的一些关键交互接口:
- client提交任务到RM,RM给出最优的资源分配方案
- Application Manager可以和RM索取资源(container),可以在请求中指出是否需要“程序贴近数据”等参数要求
- 监听Node Manager上报的机器资源情况
- RM可以要求Application Manager释放资源,如果Application Manager不配合,一定超时时间后,RM有权利要求Node Manager停掉相应容器强制释放资源
Resource Manager不会做:
- RM不做任务的协调执行(如Map-Reduce框架中何时启动Reducer),不做任务级别的fault-tolerance,这些是有Application Manager来做的
- 不做任务的实时汇报
- 不做已完成任务的报表
Application Manager
- 管理每个任务的资源使用,可以动态决定增加减少任务使用的资源
- 对任务的编排进行管理,如map-reduce中启动reduce来处理map的输出
- AM尽可能的和RM解耦,不对RM做太多假设,所以AM可以执行任意用户代码不一定非要是map-reduce框架,比如spark等都可以运行在YARN平台
- AM根据任务需求向RM申请资源容器,申请时会附带上一些需求(比如容器尽量靠近要访问的数据),等RM批下来资源后,由AM启动应用(可能是map、reduce、spark等任意应用,由各自框架决定)
- AM会向RM发送心跳,这个心跳的交互同时被用作资源申请
- AM和RM的一次或多次资源请求中包括以下内容:
- 需要多少容器(如200个)
- 每个容器要多少资源(如1cpu、2g内存)
- 是否需要”计算贴近数据”
- 优先级
Node Manager
每台机器上会有一个NodeManager进行管理:
- 监控每台机器上的资源可用情况,报告执行失败,对container的生命周期管理
- NM运行容器时会负责拷贝相关依赖(数据、可运行程序等)
- RM和AM都可以命令NM终止容器,容器终止运行后,NM会进行相关资源回收
- NM提供可编程接口,在容器运行结束时,允许用户做一些自定义操作(如map-reduce框架中,map结束后要把结果发送到reduce端)
Spark
Map-Reduce在业界取得了巨大的成功,但是它也不是银弹,Map-Reduce对数据的使用采用的方式是“阅后即焚”,即读过一次后就丢弃掉,如果还需要使用要重新再运行一个Map-Reduce任务重新从HDFS上再读一次数据。这对一些应用来说是很低效的,比如:
- 机器学习任务,在参数学习时往往需要对同一批数据进行多轮的迭代,如果每轮迭代都创建一个Map-Reduce任务去重新load一遍数据就太浪费了
- 对一些数据集可能有不少查询统计工作要做,更加明智的做法是把数据缓存在内存里,每次直接读内存数据避免反复读取硬盘数据
Spark就是针对这种“内存导向型”的应用提出的解决方案。Spark的核心模型是resilient distributed dataset(RDD)数据结构,该数据结构可以缓存在分布式机器的内存中,随时可以使用,而且支持容错机制,即使部分机器宕机,仍然可以恢复出该数据。
spark利用RDD的抽象机制,把数据尽可能hold在内存中,这在一些经典的机器学习问题上的训练速度可以比hadoop快十倍以上。
总体上说,Spark编程模型包括三部分:
RDD 数据模型
RDD的来源只有两种:
- 基于存储数据构建
- 基于其他rdd上的操作得到
RDD的存在形式:
- 内存中的java对象(最快)
- 内存中的序列化数据(使用更少内存)
- 硬盘中的数据(使用硬盘)
当内存中无法存储所有rdd时,会采用lru的方式换入换出
RDD的表示:
- rdd是一种简单的基于图的表示来实现的
- 表示RDD的五个关键元素
- partitions集合
- 依赖的上一步的父RDD
- 基于父RDD计算出次rdd的计算方法
- 元信息(关于partition方法)
- 数据保存位置
- 对父rdd的依赖区分为两种narrow,wide
- narrow是此rdd的数据来源只来源于父rdd的一个partition,这样计算的时候可以在父rdd存储的机器上计算出全部内容,恢复也是一样的
- wide是此rdd的数据来源是父rdd的多个partition
RDD的管理:
通常由spark系统决定rdd的管理,同时spark也给用户提供了接口,支持用户对rdd进行操作:
- 用户可以告诉spark系统哪些rdd后续会被反复使用,以及他们存储在哪里(是否保存在内存)
- 可以按照一定规则设置rdd保存
- rdd是lazy和“瞬时”(ephemeral)的,只有在需要时才真正计算,否则只是记录计算方式,并不真正发动计算
RDD的好处:
- RDD因为是只读的,所以RDD带来一个好处,它不需要类似其他共享内存的方案需要checkpoint来容错,RDD的handler只是记录这个rdd是如何计算得到的,这样即使机器宕机,仍然可以重新计算恢复
- RDD因为是只读的,所以当某些任务计算的特别慢的时候可以通过类似mapreduce那种后台任务转移(到其他机器上进行计算)的方式
- rdd可以尽量在靠近文件的机器上构建(减少网络传输)
- rdd可以支持降级操作,如果内存放不下,可以持久化到文件中
基于RDD的并行操作
支持基于rdd的操作,例如:reduce、collect、foreach。。。
共享变量
- 广播变量
- 累加变量
Spark的Stream Process
Spark虽说是支持流式处理,但处理方式仍然是batch的模式,只是这个batch的大小会比较小,这点不同于storm,storm每条数据都会进行一次计算。spark stream(D-stream)方法是把流式计算理解为一系列很短时间间隔的批量计算
D-stream的低延迟:
不像hadoop需要把状态持久化到文件中,spark可以通过rdd的手段来把需要的数据cache在内存里,所以可以保证较低的延迟
错误恢复:
错误恢复可以利用每台机器分别恢复rdd的不同partition来做到并行恢复,加速恢复过程
模型一致性:
可以理解为模型一直在计算,在旧的数据算完之后,开始迭代新的训练样本
Storm
storm是一个分布式的、支持错误恢复的流式处理系统(基于YARN或Mesos),设计目标如下:
- 可伸缩
- 集群可以容易的增加减少机器,而不必中断正在计算的流逝程序
- 容错性
- storm部署在大规模集群,宕机是常态,系统收到的影响应当尽量小
- 可拓展
- storm拓扑服务里应该可以随时调用外部服务(比如查询mysql)
- 高效
- storm是一套实时计算框架,必须保证低延迟,
- 易管理
- storm在twitter是核心服务,必须保证容易管理,不允许停服务
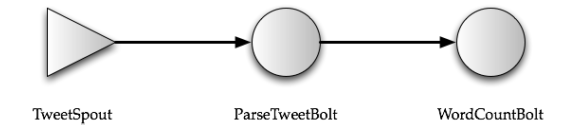
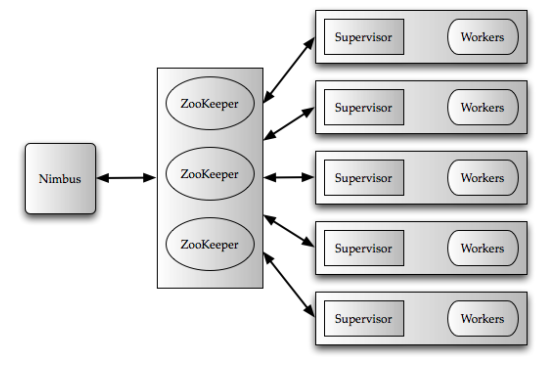
storm架构抽象:
- 一个拓扑结构,节点表示计算,有向边表示数据流(注意storm拓扑是支持环的)。
- 抽象了spout和bolt两种类型的节点,spout负责从上游系统拉数据(如kafka),bolt负责处理收到的数据然后推给下游
- Nimbus(master node)负责分发和协调拓扑结构的执行,类比于hadoop里的jobtracker,利用zookeeper协调worker nodes
- worker process负责真正的计算执行,一台机器可以有多个worker process
- 每个worker process运行在一个jvm里,每个work process里有多个executor,每个executor是work process里的线程。一个具体的task(spout或者bolt)会落到一个具体的executor
- 每台工作机器上存在Supervisor
- 每15s,和Nimbus保持心跳
- 每10s,从nimbus查询新任务,下载新任务的jar包等
- 每3s,标记本机的worker process的状态valid, timed out, not started, or disallowed
- 截止到论文发表,需要手动指定每个spout和bolt具体运行
- Message flow inside a worker:每个worker有两个线程worker receive thread和worker send thread,每个executor有两个线程user logic thread和executor send thread.
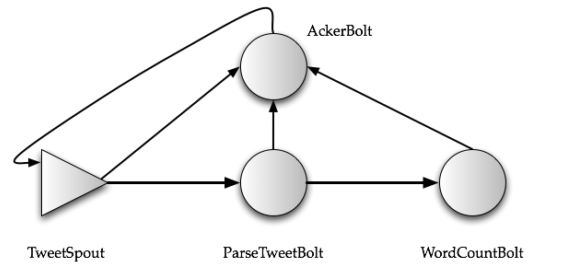
storm支持两种数据保证:
- 至少消费一次
- 需要一个“acker”去保证数据流的到达性。需要上游节点hold数据,一旦下游节点成功,上游释放掉hold的数据,一旦下游返回失败或者长时间没反馈,就重新发送hold的数据
- 至多消费一次
- 关闭ack机制即可
在Twitter大部分storm拓扑在twitter是小于3个节点的,最长的有8个节点,99%的拓扑返回时间接近1ms
PS: 《Storm @Twitter》 paper里有大规模集群应用场景下调优zookeeper的经验,后续用到可以参考
Flink
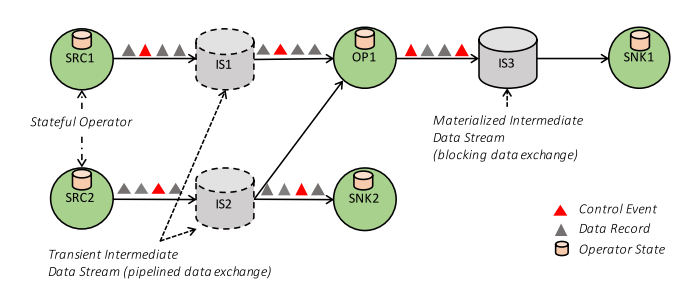
Flink希望把批处理和流处理都规约到统一的一套流式处理系统里,它的架构模型包括Flink Client、Job Manager、 Task Manager十分类似Hadoop 1.0 里的client、jobtracker、tasktracker。 Flink会把任务抽象为有向图,节点是一些处理操作(operator),边代表信息流传输(数据或事件)。
Flink的数据流传输:
- 两种传输模式:
- Pipelined 数据不停地从生产者传递到后面消费者,流式
- Blocking 数据会被block直到生产者完成全部内容生产,才传递给后面消费者
- 生产者产生数据会先进到buffer中,下面两种情况之一发生,会把buffer里的数据送到消费者(同时考虑了延时和吞吐)
- buffer满了(一个buffer可以缓存多条数据)
- 消息在buffer中等待超过一定时间
- Flink在传输数据的数据流中也会参杂一些control event,各个节点的operator收到control event后会执行相关动作
- checkpoint 做checkpoint用于错误恢复
- watermarks 通知时间流处理进度
- iteration barriers 通知进入到最后一轮数据处理
- 一旦Flink中的数据流被划分为多个operator并发消费,或者数据被广播等操作之后,Flink就不在保证数据流的顺序了,如果业务上真正关心这个由业务opeartor自己保证
- Flink保证内容被消费且仅被消费一次,容错恢复基于Asynchronous Barrier Snapshotting(一种checkpoint方法)
Flink实现迭代算法比较容易,只是在流处理的有向图的最后一个节点加一个条反馈边到初始节点
Reference
-
《Spark: cluster computing with working sets》
-
《Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing》
-
《Discretized streams: an efficient and fault-tolerant model for stream processing on large clusters》
-
《Storm @Twitter》
-
《Apache Hadoop YARN: Yet Another Resource Negotiator》
-
《Apache Flink™: Stream and Batch Processing in a Single Engine》
联系我: